・上一文章:基于高可靠微波感应的人体传感器设计
・下一文章:51单片机在微机自动交换系统中稳定运行的设计方法

从图6可见loadaa、loadbb、calcimatrix三者的时序满足浮点矩阵运算的时序图,在前两者数据加载后,即可获得calcimatrix上升沿,进行矩阵相乘。输出结果分为4个大组,各大组有8小组,每一小组由8个数据组成,具有较好的计算结果。
4 性能比较分析
4.1 性能比较
将第3节设计的16阶矩阵相乘电路与Altera自身提供的IP核进行比较。同时以8阶矩阵相乘为基,以第2节的方式设计4×4阶数选实矩阵电路,套用于32×32阶矩阵运算中,与Altera的IP核比较。IP核使用最高性能运行,同时以资源消耗、浮点操作数[5]、最高时钟频率、吞吐量作为比较准则,其中浮点操作数的计算表达式为:

依据以上浮点操作数计算方式,使用Quartus10.1软件进行编程,映射到Stratix III系列的器件中,可获得相应的对比表如表1所示。

从表1结果可见改进的浮点运算电路在ALM的资源占用减少了许多。原因为在矩阵规模增大时,只使用了8阶浮点矩阵运算,浮点IP核中的乘加核数量不变,所以消耗的浮点相乘单元不变,同样增添的浮点加法器也只消耗了不多的ALM资源。而对于改进的两类矩阵相乘都只使用8阶矩阵乘法,所以在乘法器和M9K存储器这两类逻辑单元的消耗不变。为了达到较好的性能,需要少量外围存储器处理数据的流动和浮点相加运算,但整体存储器消耗降低。观察吞吐量可知,套用的数选式矩阵相乘模块,当阶数增大时吞吐量降低,幅度明显,而选择2阶数选矩阵具有乒乓结构,性能有所提升。同理适用于浮点操作数的情况。最后整个运算电路的最高时钟频率始终是提升的。与Altera公司的IP核比较,改进的16阶浮点矩阵运算电路性能较好,而32阶运算电路性能却未达到要求。
对高阶矩阵进一步分析,在32阶运算电路的设计中,使用16阶浮点矩阵为乘法运算部分,以2×2实矩阵运算电路为核心,能够提升32阶电路的运算性能。
4.2 精度分析
以16阶矩阵的运算进行精度分析,取乘矩阵与被乘矩阵各16个数据进行计算分析,列出表2数据,其中B矩阵为现有数据的转置,以Matlab和FPGA运算结果进行对比。
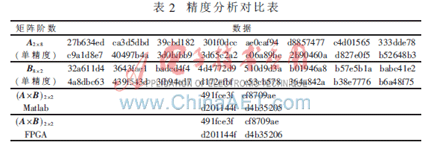
从Matlab与FPGA计算结果可见,计算输出近乎完全相同,相差的数据值也是由于Matlab在计算中需要先转化为双精度运算后才转化为单精度数,从而得出FPGA计算具有较高的精度。
本文利用IP核性能稳定、使用方便等特点,对现有的单精度浮点矩阵运算进行改进,采用矩阵嵌入式的形式,将浮点运算IP核嵌入到2阶数选实矩阵模块中,降低存储器和计算资源消耗,提升了系统吞吐量、浮点运算性能和运行最高时钟频率。这种改进的浮点矩阵乘法器对降低资源消耗、提升系统性能具有重大意义。同时,利用VHDL语言编写,具有模块化设计思想,使得本设计可移植性强、通用性好,只需要在现有IP核的基础上进行小规模改进,即可拥有较高性能,具有一定的工程实际意义和应用前景。
参考文献
[1] 田翔,周凡,陈耀武,等.基于FPGA的实时双精度浮点矩阵乘法器设计[J].浙江大学学报(工学版),2008(9).
[2] Altera Corp.Floating-Point megafunctions user guide.2010.
[3] 蔡敏,闵言灿.全流水线结构双精度浮点乘加单元的设计[J].微电子学与计算机,2010(1).
[4] 江思敏.VHDL数字电路及系统设计[M].北京:机械工业出版社,2006.
[5] 余江洪,肖燕成,朱宗柏,等.基于LinPACk的高性能计算机集群的并行性能测试[J].船电技术,2009(5).





