・上一文章:基于ARM2410的WLAN电子邮件移动终端
・下一文章:低轮廓车载卫星通信天线的跟踪设计
随着信息技术的发展,网络通信、信息 安全 和信息家电产品的普及, 嵌入式 MCU正是所有这些信息产品中必不可少的部件。目前国内一些科研院校和半导体公司都在致力于研发自主设计的 嵌入式 微控制器,这对我国的半导体产业、电子产品产业的发展具有重要意义。
这里描述了一款自主研发的16位嵌入式微控制器(A8096)的设计与实现,基于RTL级设计方法使用VerilogHDL进行设计描述,在设计中,采用硬布线控制方式,减少了面积和功耗,同时MCU兼容了MSC-96指令集,目标是可以应用于实际嵌入式系统项目中。
1 总体设计
1.1 MSC-96体系结构
图1所示为MSC-96体系结构。Intel 8096微控制器是由通用寄存器阵列、算术逻辑单元(RALU)和微程序控制器等模块组成。其采用的是微程序控制方式,需要使用一个片内ROM 存储 器,因而会造成面积和功耗都会较大。
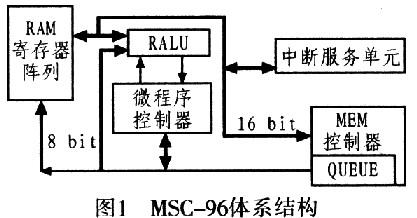
MCU内部的寄存器阵列通过一个控制器和2条总线与RALU相连。这两条总线是8位的A-BUS和16位的D-BUS。DBUS只用于RALU与寄存器之间的数据传输,而A-BUS用作上述传输过程中的地址总线。当MCU通过寄存器控制器访问片内外寄存器时,A-BUS可作为多路转换的地址/数据总线。
1.2 A8096总体结构
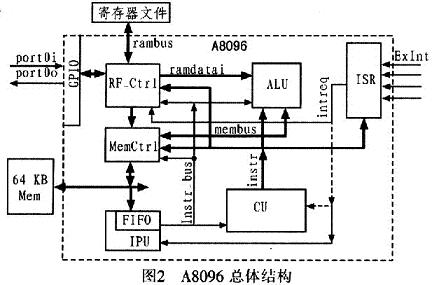
为了减少面积和功耗,A8096采用硬布线逻辑控制方式取代上述的微程序控制器。依据MSC-96的体系结构,A8096主要功能模块包括:IPU(InstrucTIon Pre-fetch Unit。指令预取单元)、CU(Control Unit,控制单元)、ALU(ArithmetIC Logical Unit,算术逻辑单元)、MEM_C-TRL(MEM控制器)、RF_CTRL(寄存器堆控制器)、ISR(Interrupt Service Routine unit,中断服务单元)、GPIO(General Purpose Input Out-put,通用输入输出单元)等主要功能部件。其结构如图2所示。
1.3 系统总线
A8096采用3条总线:一条是MEM总线,用于IPU和MEM CTRL对程序空间和数据空间的读写控制;16 bit的数据线,16 bit的地址线,读写信号memrd/memwr;一条是内部寄存器阵列(Register File)总线,用于RF_CTRL对内部寄存器阵列的读写访问,地址线是8 bit的,数据线为16 bit,读写信号为rf_rd/rf_wr;一条是SFR总线,用于访问数据空间地址在00H~19H的特殊定义的寄存器空间。8 bit的地址总线,16bit的数据总线,读写信号sfrrd/sfrwr。另外IPU和MEMCTR的数据交互是通过8 bit的数据线instr_bus完成的,其作用是从预取指令队列中将指令传给CU单元等。
2 MCU设计与实现
2.1 MCU工作原理
A8096通过IPU(指令预取单元)指令预取,并存放在预取指令队列中,CU(控制单元)从IPU指令队列中取指并进行译码,产生控制时序等信号。ALU单元、RAM控制器、MEM控制器等部件中均有译码模块,依据当前指令和当前指令周期主动工作。如:RAM控制器在加法指令的相应周期取操作数送往ALU单元,ALU在相应周期接收数据,然后进行运算并将结果输出。
2.2 MCU启动过程
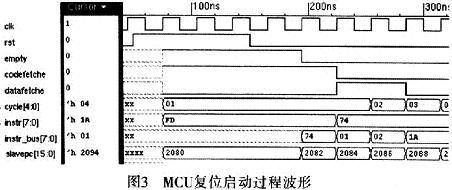
在上电复位时,MCU处于复位态(rst信号有效)。复位时,IPU单元中的指令队列清空(empty信号有效),总线处于空闲态,IPU立刻进行指令预取动作,程序空间的首地址(2080H)指令即被取人指令队列,随后队列空信号(empty)无效,同时指令被发送出去(instr_bus)。在复位同时,控制单元(CU)的取指信号(codefetche)即一直有效,在指令队列空信号empty无效后(在empty无效之前CU一直等待),指令即通过instr_ bus进入了CU,指令操作码被存入了指令寄存器,如图3中instr寄存器更新为加法指令的操作码74。至此,MCU完成了复位、自动取指操作,并开始往下执行该指令,IPU单元也会继续进行指令预取操作。
2.3 指令执行过程
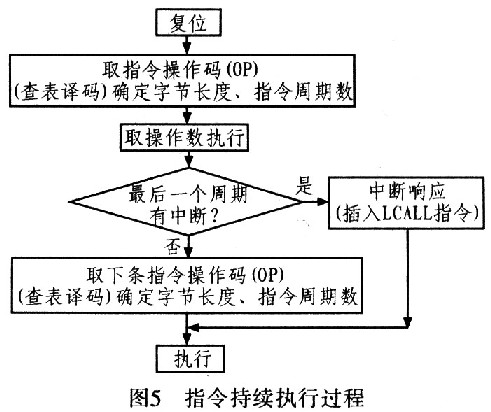
在A8096中,有两级指令预取概念:一级是指令预单元IPU利用总线空闲从程序空间不断预取指令存入指令队列中;一级则是指令执行过程中的指令预取,当一条指令执行到最后一个时钟周期时,CU单元就会发送取指信号,进行指令执行级的预取指动作,下一条指令的操作码即被预取出来(指令队列为空时需等待),并立刻进行译码确定指令的字节长度和指令执行周期数。
如图4所示,在加法指令的最后一个周期(cycle=05),CU单元取指信号codefetche有效,则下一条指令的操作码(6C,乘法操作码)被预取出来,同时进行查表译码确定其指令字节长度和指令周期数,随后操作码被存入指令寄存器instr中(此时,指令周期计数器cycle又从01开始计数)。后面乘法指令的操作数也会不断被取进来执行,直到乘法指令最后一个周期时,又将下一条指令的操作码预取进来。
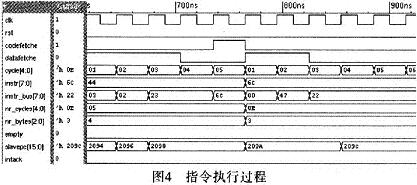
需要说明:codefetche为取操作码信号,datafetche为取操作数信号。在指令最后一个周期时若有中断请求,则插入LCALL指令进行中断处理,读取下一条指令。其流程如图5所示。
2.4 指令译码过程
在MCU设计过程中,首先完成对各条指令的指令分析工作,确定每个周期该做的动作,然后各部件依据指令分析表进行相关的指令译码(RAM控制器只译RAM要做的动作,ALU只译ALU要做的动作)。过程描述如下:在预取操作码时,CU单元对操作码进行译码确定指令的字节长度(nr_bytes)和指令周期数(nr_cycles)。然后CU依据指令字节长度(nr_bytes)取操作数,其他部件依据指令和当前指令周期(curcycle)执行相应的指令操作。表1为加法指令分析表,下面以加法指令的译码过程来说明整个译码流程:
1)加法指令 ADD OPl OP2(将OPl+0P2结果写入OPl中);其目标码格式为:ADD OP2 OPl,其中OPl和OP2均为操作数地址。
2)0周期 实际指上一条指令的最后一个时钟周期,此周期codefetche取指信号有效,IPU单元将指令送入CU单元确定了指令周期和指令长度。
3)l周期 取操作数信号datafetche有效,op2(地址)进来,被送入RAM地址线,发读信号(从RAM寄存器阵列取操作数2)。
4)2周期 操作数2被取入,并存入ALU中的a寄存器;此周期取操作数信号datafetche有效,opl(地址)进来,被送入RAM地址线,发读信号。
5)3周期 操作数l被取入,并存入ALU中的b寄存器;加法器立刻进行a+b运算。
6)4周期 将加法结果放到RAM数据线上,地址线=opl,发写信号。将加法结果写回到opl中,并依据结果对PSW进行处理。
7)5周期 无动作,用于写回操作的过程。
3 验证结果
3.1 仿真验证
芯片的功能与结构设计,只是设计流程的一部分,为保证最终设计成功,必须对其全面仿真与功能验证。对MCU的 测试 方法如下:1)功能模块的单元 测试 ,验证模块的功能正确性,包括接口时序等。2)系统集成测试,首先编写简单的机器码测试向量进行初步调试:然后使用编译器写汇编程序,编译成二进制机器码进行程序功能测试。在集成测试中,编写汇编测试程序,用编译器编译成机器码,在Cadenee NC下运行这些测试程序进行仿真测试。对每条指令均测试了其各种寻址方式,且测试程序自动向DEBUG寄存器写测试结果,以方便调试。经过复杂的测试和不断修正,验证结果显示MCU指令执行的正确性。
3.2 FPGA验证
使用的FPGA器件是StraTIxⅡ型号为EP1S40F780C7。综合结果显示:A8096使用3 565个LE(Logic Element)。时序分析结果:A8096可以运行在49.93 MHz的时钟频率下。A8096占用FPGA资源分布情况如图6所示。

4 结论
本设计中,采用RISC技术中的硬布线控制逻辑,有利于减少MCU面积、降低功耗以及提高MCU执行效率,FPGA实现表明其只占用了3 565个LE单元,工作时钟可达50 MHz。同时该MCU具有很强的扩展性与实用性,应用领域广泛,可方便与定时器、串行通讯接口(I2C)、串行外围接口(SPI)、模数(A/D)转换器等外围功能单元组成各种嵌入式系统,完全具备实际应用价值。





