・上一文章:扩声系统中的DSP问题解析
・下一文章:基于TMS320C6x11系列DSP的图像获取方案
摘 要: 针对固定码长Turbo码适应性差的缺点,以LTE为应用背景,提出了一种帧长可配置的Turbo编译码器的 FPGA 实现方案。该设计可以依据具体的信道环境和速率要求调节信息帧长,平衡译码性能和系统时延。方案采用“自顶向下”的设计思想和“自底而上”的实现方法,对Turbo编译码系统模块化设计后优化统一,经时序仿真验证后下载配置到 Altera 公司Stratix III系列的 EP3SL150F1152C2 N 中。测试结果表明,系统运行稳健可靠,并具有良好的移植性;集成化一体设计,为LTE标准下Turbo码 ASIC 的开发提供了参考。
LTE(Long Term Evolution)是3GPP展开的对UMTS技术的长期演进计划。LTE具有高数据速率、低延迟、分组传送、广域覆盖和向下兼容等显著优势,在各种“准4G”标准中脱颖而出,最具竞争力和运营潜力。运营商普遍选择LTE,为全球移动通信产业指明了技术发展的方向。设备制造商亦纷纷加大在LTE领域的投入,其中包括华为、北电、 NEC 和大唐等一流设备制造商,从而有力地推动LTE不断前进,使LTE的商用相比其他竞争技术更加令人期待。
Turbo码[3]以其接近香农极限的优异纠错性能被选为LTE标准的信道编码方案之一。对Turbo编译码器进行 FPGA 集成设计,能够加速LTE的商用步伐,具有广阔的应用前景。在不同的信道环境中,通信系统对信息可靠性和数据实时性具有不同的指标要求,实际应用中必须对二者进行适当折中。因此,硬件设计一种纠错性能与译码时延可灵活配置的Turbo码编译码器更具商业价值。
Altera 公司推出的功率优化、性能增强的Stratix III系列产品采用了与业界领先的Stratix II系列相同的FPGA体系结构,含有高性能自适应逻辑模块(ALM),支持40多个I/O 接口 标准,具有业界一流的灵活性和信号完整性。Stratix III FPGA和Quartus II软件相结合后,为工程师提供了极具创新的设计方法,进一步提高了性能和效能[5]。Stratix III L器件逻辑单元较多,为帧长可配置Turbo码编译码器的FPGA设计提供了便利条件。
Turbo码的误码性能在很大程度上取决于信息帧长,信息帧越长,译码性能越好,代价是译码延时的增大。基于这一点,本设计提出一种帧长可配置的Turbo码编译码器的FPGA实现方案,详细介绍了该系统中交织器的工作原理,并对时序仿真结果和功能实现情况进行了分析,为LTE标准下Turbo编译码专用 集成芯片 的开发提供了参考。
1 帧长可配置的Turbo编译码器的系统结构
LTE标准中,信道编码主要采用Tail Biting(咬尾)卷积码和Turbo编码[4]两种方案。其中Turbo码码率为1/3,由两个生成多项式系数为(13,15)的递归系统卷积码(RSC)和一个QPP(二次置换多项式)随机交织器组成,采用典型的PCCC编码结构。
根据Turbo码编译码结构原理可知,信息帧长关键取决于交织深度的大小,如果交织器能够根据不同帧长参数自动植入不同的交织图样,并对其他模块进行相应参数控制,即可实现设计功能。由此得到可配置Turbo编译码器的设计思想:在编译码之前,由键盘 电路 输入信息帧长,系统据此对编译码器进行初始化,主要包括设置电路中 存储器 的深度,计算、存储交织图样,并通过 LCD 同步显示帧长信息;初始化过程结束时输出状态标志位,编译码器进入准备状态,一旦有数据输入,即启动编译码流程。由此得到Turbo编译码器系统结构图如图1所示。
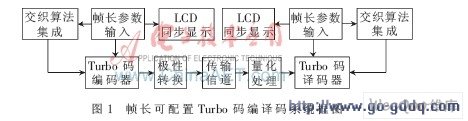
图1的Turbo码编译码器中,所有有关信息长度的参数均设置为输入变量,包括存储器深度、 计数器 周期等,以方便配置。
2 FPGA功能模块的设计与实现
2.1 交织模块的设计
交织器是Turbo编译码器的主要构成部分之一,其能否根据帧长参数产生相应的交织图样也是本设计的关键所在。LTE标准中规定交织器采用QPP伪随机交织方案,交织长度范围为40~6 114,该方案对不同帧长产生不同的交织图样,能够有效改善码字的汉明距离和码重分布。假设输入交织器的比特序列为d0,d1,…,dK-1,其中K为信息序列帧长,交织器输出序列d′0,d′1,…,d′K-1。则有:
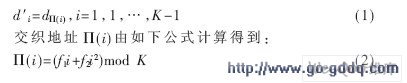
参数f1和f2取决于交织长度K,具体值可参见参考文献。
传统交织器的FPGA设计一般采用软件编程的方法。根据通信协议,将所确定帧长的交织图样预先计算出来,生成存储器初始化文件(.mif或.hex格式)载入到ROM中[6]。这样虽然降低了硬件复杂度,却不能自行配置编码帧长,缺乏灵活性和通用性。因此,设计中将交织算法集成于FPGA内部,需要改变信息帧长时启动交织器重新计算交织地址存储于RAM中。QPP交织器的硬件结构框图如图2所示。
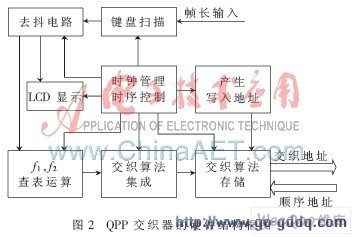
图2中,在系统初始化阶段,由键盘电路采集输入的信息帧长K,经消抖处理,一路传输给LCD同步 显示模块 ,另一路传送到f1、f2运算单元,查表得到f1、f2的值,提供给交织算法集成模块。
交织算法集成单元是交织器设计的核心部分。主要功能是根据LTE协议标准以及参数K、f1、f2,在时序 控制模块 的约束下,计算交织地址。运算过程中,将FPGA不能综合的对任意整数取余的运算,均转化为固定次数的加减循环操作,在时钟管理模块的控制下,采取小时钟计算、大时钟输出的措施,保证交织数据的正确读取。
计算交织地址的同时产生写入地址,将交织地址顺序存储到双口RAM中,由此完成了交织器的主体设计。随后发送握手信号,可以开始Turbo码编译码流程。
因为并不是每帧信息编译码时都需要运行交织算法模块,所以只是在初始化阶段载入交织地址,使交织算法与编译码器分时工作。调用交织器模块时只需将顺序地址输入到双口RAM的读地址端,便能得到既定帧长的QPP伪随机交织地址,不会增加译码延时。得到交织图样以后即可进行交织、解交织过程。
2.2 Turbo码 编码器 的设计
在完成交织模块的基础上对Turbo码编码器进行FPGA设计。Turbo码编码器由RSC(递归系统卷积码)子编码器、交织器、复接电路等构成,硬件实现框图如图3所示。
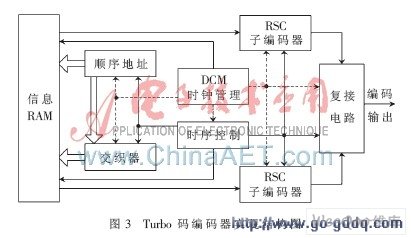
系统初始化完毕后,交织器已存储有对应帧长的交织图样,编码器首先接收到一帧信息存储于RAM中,开始信号启动编码过程。在时钟管理模块和时序控制模块的指引下,计数器产生顺序地址,再按该顺序地址访问交织器得到交织地址,分别以顺序地址和交织地址从存储有信息序列的RAM中读取数据进入对应的RSC进行编码,同时复接电路对信息位和校验位进行并串转换,一帧信息编码完毕对子编码器做归零处理。
2.3 Turbo码译码器的设计
Turbo码译码器相对于编码器来说硬件结构更加复杂,根据译码原理和交织器实现方式,得到译码器实现结构图如图4所示。
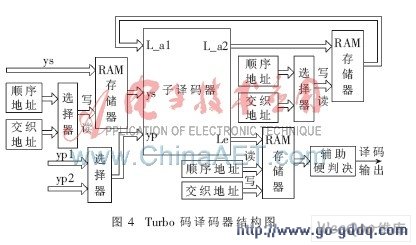
为节省硬件资源,本文设计的Turbo码译码器采用子译码器单核复用的结构模式。当子译码器模块作为子译码器1时,信息比特顺序写入存储器后顺序读出到子译码器中,L_a2以交织地址写入存储器,顺序地址读出作为子译码器1的先验信息,同时校验位选择yp1,子译码器1根据3个输入进行SISO(软输入软输出)译码运算,得到新的L_a2及L_e;此后子译码器作为子译码器2,以交织地址将ys从存储器中读出,L_a2以顺序地址写入存储器,交织地址读出作为子译码器2的先验信息,同时校验位选择yp2,子译码器2根据3个输入进行SISO(软输入软输出)译码运算,得到新的L_a2及L_e,完成一次迭代。在满足迭代停止准则以后,将L_e解交织后进行硬判决,得到译码序列。
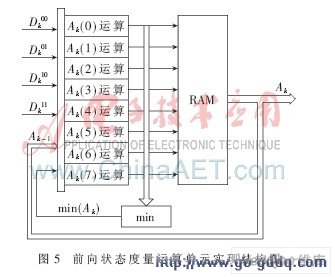
设计中,子译码器采用复杂度与性能折中的Max-Log-MAP译码算法。根据输入的信息位、校验位及先验概率信息,在时序控制模块的管理下,分别进行分支转移度量、前向状态度量、后向状态度量和对数似然比的计算及存储,以备下次译码运算调用。
依据初始化分支转移度量值,由(13,15)RSC的篱笆图,找出当前时刻前向状态度量与前一时刻前向状态度量的对应关系[7],计算当前时刻的前向状态度量。依次递推,为防止数据溢出范围,每次迭代对其进行归一化处理,得到实现框图如图5所示。后向状态度量与前向状态度量具有相似的运算结构,只是逆向递推而已。