����һ���£�����ADSL�����������Ƶϵͳ
����һ���£�����VS1003��������MP3���������
����
����PPT(Microsoft Office PowerPoint),������˾�����ı༭��ʾ�ĸ�İ칫�������ø�ʽ�����txt��chm�ȣ���Ϣ�����ṹҲ���Ӹ��ӣ��������Ӳ������Ҫ��ϸߡ�Ȼ����ĿǰǶ��ʽ�ն����õͣ���˱��ľ۽����������Ƕ����ƶ��Ķ��Ļ��������ݲ�������Ƶ����Ƶ���ⲿ���������֧�֡����������ڿ�Դ�����£�����Linux����ϵͳʵ�֡�����Ƕ��ʽ���ʽ��������ϵͳ�ܹ����м��ʽ����,����ƽ̨���ԡ���Ч�Ե��ص㡣
����1 ϵͳ�ص�
�����ý���������ݰ汾�࣬����Microsoft PowerPoint 97��2003�Ȱ汾���������һ��ϵͳ�ص㡣
������ ��������ͼ�η���������������ӵ���Լ���ר�õ�ʸ��ͼ�λ����������������ض��ĵײ�ͼ�η����������磬���ǵ�ʵ��ϵͳ��ͼ�η�������nanoX��ΪQtʱ���ý������治��Ҫ�ġ�
������ ��Ч�ԡ�����һ��ĸ�ʽ�������������ļ�Խ���ٶ�Խ�������ý��������������ļ����ٶ����ļ���С�����ء�
������ ƽ̨���ԡ��������沢����ֱ������ʾ�豸�ϻ���ͼ�κ����֣����ǰѸ��ָ�ʽԪ�ػ�����һ���ڴ������ϣ�Ȼ�������ڴ�����ӳ�䵽�����豸�ϡ����������ļ����������Ļ��С��λͼ��
������ ���������������ģ�黯��Ʊ�����ֲ�Ͳü��������������Ͳ��ú궨�壬���ڸ���ƽ̨���á�
������ ֧����д��ע�� ������ֻ�����ݳ�ȡ����ʾ����֧�ֱ༭�ͱ��棬֧����д��ע����д��ע���ı�ԭ�ĵ��������½�xml�����ļ���
������ ���Ի�������ʽ�����õ���ֽ��������16ͨ���ͺڰ�ˢ��ʵ�ֶ����л�Ч����
����2 ��ʽ����
����2.1 ����ṹ
����Microsoft PowerPointʹ��OLE2����ĵ��洢�����ļ�ϵͳ�ṹ���ƣ���������������������ɵ���״�ṹ�������������洢����������Ϳ��ٱ��档���1���У�PPT�ļ���������5����ʽ���ݡ�
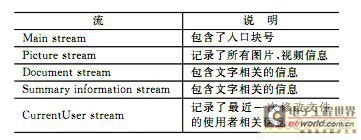
������1 PowerPoint�ļ��ṹ
����PPT�洢��ʽ����ʮ�����ƣ�small endian�ֽ���Ϊ���ɸ������ݿ��С���ݿ飬��С�ֱ�Ϊ512�ֽں�64�ֽڣ���һ�����ݿ�Ϊ��ʼ���ݿ飬�洢�����ݿ���������
����2.2 ͼ�����ṹ
����PPT�а������Ρ�ͼƬ���ı����ߡ���Բ��204����ʽ��Ԫ�أ�ͳ��ΪShape��ÿ��Shape��һ��Ψһ��ʵ������֮��Ӧ��
������ý�����ݵIJ�νṹ��ͼ1��ʾ��
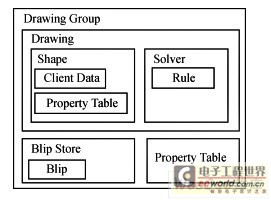
����ͼ1 ������νṹ
����Drawing GROUPΪ���ͼ�δ洢�ṹ����������һ��ͼ�ζ���DrawingΪͼ�δ洢�ṹ��Shape��SolverΪ����ͼ������Ԫ���ݡ�Blip StoreΪ�����ͼƬ����Property TableΪȱʡ���Ա���Client DataΪһ��Ԫ������Ϣ���������꣬�ı���OLE���ݺ��û��Զ������Ա���
�������������id��value�ṹ���Զ������Ա��ij��ȿɱ䡣�����������λ�ò��䡣�Զ������Ա��г��ֵ����Խ�����Ĭ�����ԡ�
����DrawingΪһ�����������������е�ͼ�ζ���Ĺ��ϣ��������뷽ʽ����ߵȡ�
����3 �������
�����������Ƕ��ʽ���ʽ��������ϵͳ�ܹ�Ϊ���������������Ǹ����Դ�ļ����н���,�����м��ʽ��Ҫ�����ݵ�ģ�顣
��������������ڲ��ܹ���ͼ2��ʾ��
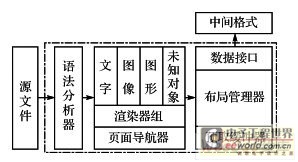
����ͼ2 ��������ܹ�
����3.1 �������
�����������Ϊ���������ݣ����Ϊ�ṹ�����ݹ���ģ��ʹ�á�PPT��ʽ�ļ�¼����id��value�ṹ��id��valueռ�ݹ涨���ֽ����������������ʶ���¼id������ȡvalue��
����3.2 ������
������������ݴ��ļ�ϵͳ�����ڴ棬����I/O��ת���ɽṹ�����ݣ�����DOM�ṹ�����ļ�������ܹ���
������ģ�����ҳ�浼�����á�PPTʹ��OLE2����ĵ��洢�������ͽ��ֻ�洢������������Ϣ�����ڲ���Ҫ������ʾ��ҳ��ֻ�洢������㣬��ʱ��չ������Ҫ��ʾ��ҳʱ���ٴӸý������չ�����Ӷ������˲���Ҫ���ļ���ȡ�����ֲַ�װ�ط���������˴��ٶ�,���Ҷ��ڴ��ĵ��������ٶ�ֻ�͵�һҳ�ĸ��ӳ̶��йء�
�������⣬Ϊ�˸��õ�������������һϵ�е������ṹ���磺���ݿ�����������Ŀ¼����ͼ���������������û������������ı�����ĸ�������ȡ�
�����ļ����ȡ��汾�š������ļ��Ϸ��Ե���Ϣͨ����ȡ��ʼ�����á�����֮���Ҫ��ʼ��������Ҫ��ȫ��������
������ ���ݿ����������ļ��Կ�Ϊ��λ�洢���Ҳ�����������������źͿ���ƫ�������Է���ؽ���Ѱַ������
������ ������Ŀ¼���������洢���ݵ���ʼ��źʹ�С������Ѱַ������������ֻ�ڵ�ǰ�鷶Χ��,��������ǰ��ɶ�����ʱ��ͨ����ѯ���������ҵ���һ��Ŀ�š�
������ ����ͼ��������������
������ �����û�����������Ϊ�˿��ٱ��棬PPT��������ʽ�洢����ÿ�α���ʱ��ֱ������ҳ�渱�����ӵ��ĵ�ĩβ������ʽ�洢��ȱ���������������磬�е��ļ�ֻ�м�ҳ�����ļ���С��MB������ʮMB���ļ�ʵ�ʴ�С���Ĵ����йء�
������ �õ�Ƭ�ı���������Ϣ���Ű�Ԫ���ݶ����洢�����ı��洢���ı����У��洢�Լ��Ű���Ϣ�洢��ҳ��������ҳ���������洢�˴��ı����ı����е�λ�á�
������ ĸ������,ĸ��һ����Ϊ��������ҳΪ��λ˳�δ洢����Ϊ����ֽ��ʾ�Ҷ�ͼ���������ĵ����Ժ�������û��Ķ�ʱ����ȥ��������������Ӱ�쵽�ļ�������
��������ʽ�洢�Ļ���˼���ǣ�ÿ���IJ���һ���û���Ϣ���洢�ĵĿ�ţ���ǰ�û���Ϣ����ָ����һ���û���Ϣ���Ӷ�����һ���û��������������û������������ҵ����һ���ġ��������ݿ���ֱ�Ӷ�����
����3.3 ���ֹ�����
����������Ļ���ֺ�ͼ����������ֹ�������Ϊ��ͬ�ľ���������ʶ����������͡�Ȼ��ֱ����õ������֣�ͼ�Σ�ͼ����ӳ�䵽��Ļλͼ�ϡ�
����3.4 ���ִ�����
����PPT��ʽ����������Ͳ�����Ը��ӣ����Է�Ϊ���ĺ�ͼ����Ƕ�������֣������������ĵIJ���Ҳ��Ҫ�����ִ�������Ը����ı����Ű��ʽ�����Խ��н����Ͳ��֣���������ԭ�ĵ��İ�ʽ��Ϣ��
�������ִ������̷�ΪԤ�Ű��ҳ���Ű������֣�Ԥ�Ű渺�������ģ����������ȡ�ַ������������Ϣ��ΪFreeType�����룬�����ɵĵ�����ģλͼ��仺������Ȼ���ϱ�ߺͶ��䷽ʽ��ӳ�䵽ҳ����ʾ�����������ֽ���ԭ��ͼ��ͼ3��ʾ��

����ͼ3 ���ֽ���ԭ��ͼ
����3.5 ͼ����Ⱦ
��������ͼ�λ��ƺ����ͼ������ռ�ת�������������治������ͼ�η�������ӵ��ר�õ�ʸ��ͼ�λ��ƿ⡣�ܹ���ͼ��ֱ�ӻ��Ƶ�ҳ��λͼ�У���������ʾ�ء�
��������ֱ��,���ߺͶ�������ֱ�����˾����Breshman�㷨�����α������������㷨,��ɨ����������㷨3�ֳ����㷨��Ϊ�����������Ч�ʣ����ڸ�������ȡ�����㡣����֤���ڸ���������Ч�ʲ��ѵ�Ƕ��ʽϵͳ��Ҳ�ܵ���Ϻõ���ȾЧ����
�������ͼ��(Drawing GROUP)������һ��ͼ�ζ���,������Dom�ṹ���ӽ��ʹ������ڸ���������ռ䡣��ˣ�ͼ�δ����ܹ��ݹ�ؽ�������ת��,����ͼ�λ������丸��������ռ��ڡ�
����3.6 ͼ����Ⱦ
����ͼ����Ⱦ������Cximageͼ����ͼ�������ع�������һ��ת���ɻҶ�ͼ�������Ļ��������
�����ļ���ͼ��Ͷ�ý����Ϣ�洢��ͼ�����У�ͨ��FBSE (File Blip Store Entry)���������Ƕ����˽ṹ�壺
����typedef struct _FBSE{
����MSOBLIPTYPE imageType;
����ULONG id;
����ULONG size;
����ULONG cRef;
����ULONG offsetInDelayStream;
����}FBSE;
����4 �Ż�����
�����û�����ϣ��ϵͳԽ��Խ��,����Ƕ��ʽϵͳ����Ƶ�ϵ͡��ڴ��С������,����һЩ�������Ƚϴ�Ĺ���,���Ѵﵽ�����Ч�������DZ�����������Ӧ���˶�ҳ�滺����ƺ��첽���л��Ƶ��Ż����ԡ�
��������Ⱦ���첽���еع�������һ������������Ⱦ�������������ύ����Ļ��ʾ������ֽ����ˢ���ٶ�Ϊ1 s���������ˢ����Ъ��������Ⱦ����������ٲ��þֲ�ˢ���ķ�ʽ����������ˢ�µ���Ļ�ϡ����������ٶ�ȡ������Ⱦ�ٶ���������һ�������⣬�첽ִ�в��������룬�����ʱ�û���ҳ��δ��ɽ����̻߳ᱻ��ֹ�����������߳���������һҳ�����磺��һҳͼ�Ļ��ŵĻõ�Ƭ����ʱ����ʾ���֣������ʾ��ͼ���Ҳ��������û����룬�����û���������������ҳ��ֹͣ���м�ҳ�����ᱻ��ֹ��
����5 ��֤
��������Ƶ200 MHz�ĵ���ֽ�Ķ�����ʵ��Ч����ͼ4��ʾ��
����ͼ4 �ڵ���ֽ�Ķ����Ͻ���Ч��ͼ
�������ѡ��60�������ļ��������鼮���ʱ��2.82 s,�11.92 s.��ͼ5��ʾ��
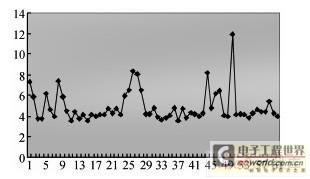
����ͼ5 �ڵ���ֽ�Ķ����Ͻ����ٶ�ͳ��ͼ
��������������÷ֲ�װ�ط���������˴��鼮�ٶȣ�����ѡ����3����һҳ��ȫ��ͬ���Ǵ�С���ϴ��PPT�ĵ���ʵ���������Ȼ�ĵ���С���ܴ��Ǵ��ٶȲ��첻�����2���С�
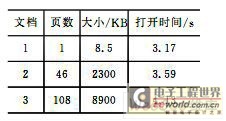
������2 �����ٶȶԱ�
��������
�������ڵ���ֽ�����Ժ�Ƕ��ʽ�豸����Դ���ƣ����Ľ����۽��ڳ���Ԫ�صĽ����ϣ������֡�ͼ�Ρ�ͼ����ȣ�������Ƕ�����(����Ƶ����Ƶ��)û��֧�֡�����δ֪Ԫ�صĽ�������Ϊδ������Ҫ����������ģ�黯����Ƽܹ�����������һ�����й�����չ�����⣬����Office�����ĵ���ʽ��OOXML���ĵ�������Ϊ���ʱ���δ��������֧��OOXML��Ƕ��ʽ��������





