・上一文章:多核处理器架构及调试
・下一文章:微控制器时钟―选择晶振、谐振槽路、RC振荡器还是硅振荡器?
特定应用的微控制器选型分类有很多种方法。从内核处理器类型和存储器总线系统入手是其中常见的一种。是选择8位、16位,还是32位架构,通常有以下几个参考标准:性能级别、可寻址存储器和系统成本。
客户有时还可能遇到各种需要多内核架构的应用,这种情况意味着用户不仅要花更多时间了解并掌握各种内核技术、外设编程技术和工具使用,还要在管理不同架构特性方面额外增加物流费用。
针对这一问题,恩智浦推出了基于32位ARM Cortex -M0处理器内核的LPC1100系列微控制器。该处理器是ARM公司Cortex-M系列尺寸最小的一款,具有32位架构性能、低功耗和超小封装等优点。LPC1100是恩智浦半导体大获成功的LPC1000微控制器系列的最新产品(参见图1),主要针对目前8/16位微控制器占主流的低成本应用的市场。

图1: 恩智浦Cortex-Mx微控制器系列
LPC1100 完全具有围绕LPC1300和LPC1700微控制器(均采用Cortex-M3内核)建立的生态系统优势。从诸如UART、I2C和SPI等标准接口到高端的CAN和USB,LPC1100外设种类齐全。LPC1000生态系统包括多家供应商提供的编译器和调试工具、各种操作系统和软件。由于 LPC1100系列微控制器Cortex-M0能够向上兼容M3内核,因此能够实现开发共享。
本文将针对过去8/16位微控制器的几个薄弱应用环节,重点介绍LPC1100的优势。此外,还将涉及LPC1100如何解决成本、功耗和代码大小等难题,以及如何提高传统8/16位微控制器应用领域的系统效率。
节能
对于门、窗或照明控制等家庭自动化应用领域,主要采用传感器连接到家庭自动化系统内部总线,这些总线和传感器从专用直流电路获取电流,大部分时间都处于工作模式。LPC1100在工作模式下出色的低功耗特点为此类应用提供了理想选择。
图2是一个从闪存执行代码并在RAM里操作动态数据的典型应用示例,显示了LPC1100在正常工作模式下几个内部系统模块的功耗情况。
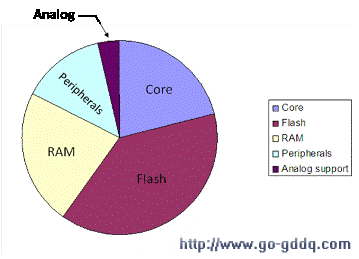
图2: 20MHz内核频率的各模块耗电量
在电流消耗总量中,Cortex-M0内核和内部存储系统所占比重最大。尽管Cortex-M0内核的处理能力超强,但是采用该内核的LPC1100在无限循环运行时的平均耗电量仅为150μA/MHz左右。
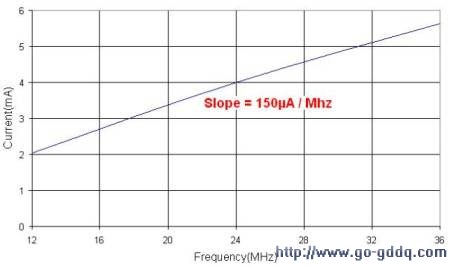
图3 正常工作模式下,从闪存执行代码的耗电量
预计在推出低功耗(LP)LPC1100新产品后,现有的LPC1100微控制器低功耗表现会得到进一步提升。工作模式耗电量有望降至130uA/MHz左右。
此外,由于M0内核采用32位架构,因此电流利用效率要高于8/16位架构。对于执行相同的计算任务,M0内核的实际运行速度可比8/16位微控制器低2-4倍,因此功耗要远低于8/16位微控制器。
对于“深度睡眠”或“深度掉电”模式,Cortex-M0内核的强大处理能力同样有用武之地,与8/16位架构相比,32位架构执行任务的时间更短,因此微控制器更多时间会处于低功耗模式运行。新型LP系列产品将大幅减少深度睡眠模式(2uA)和深度掉电模式(220nA)耗电量。
运算能力
LPC1100非常适合同时处理微控制器( MCU )基本任务和各种操作数(8位、16位或更高位)运算。嵌入快速的32位Cortex-M0内核(最大频率50MHz)并保持微控制器操作和编程灵活性(Cortex-M0 内核可以完全采用C语言)是代替16位混合系统的最好解决方案。
Cortex- M0微控制器可以轻松超越高端8/16位单片机。Cortex-M0内核的额定处理能力高达0.8DMIPS/MHz,是高端8 /16位单片机的2-4倍。由于DMIPS和MIPS有时并不能准确反映用户器件性能,因此图4根据一些通用的测试基准程序给出了各器件的相对性能。大多数常用Cortex-M0 Thumb 2指令为单周期指令,所有8位、16位和32位数据传输在一个指令周期内完成。在8位和16位单片机中处理长字乘法运算通常要花很长时间,但由于Cortex-M0内核是32位架构,恩智浦在LPC1100中采用了32x32位硬件乘法器,通过MULS指令,成功地在一个指令周期内完成了两个 32位字的乘法运算。
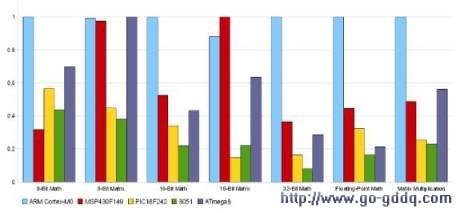
图4 Cortex-M0相对性能
除法运算可通过软件完成,Cortex-M0对于各种操作数除法运算有同样出色的表现。
对于具体的应用,复杂的计算通常会涉及多次加法、乘法和除法。图5显示了一个复杂计算的执行时间,其执行条件是从闪存执行代码,采用浮点操作数共进行5次乘法、5次加法和1次除法计算。对于浮点运算,C语言代码可通过一个特定的Cortex-M0数学库函数做优化。
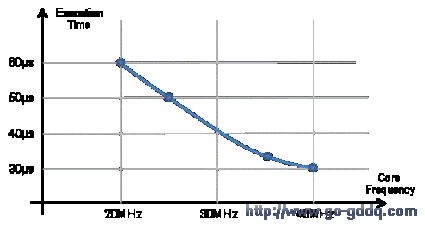
图5: 浮点运算时间实例
从数学库向RAM重新优化一些重要的函数可以进一步提升性能。应该在RAM中调用这些库函数,这样可避免从ROM页到RAM页的分配过程出现长分支,以缩短执行时间。





