・上一文章:基于wince的心电图机软件系统设计与实现
・下一文章:基于DSP和nRF24L01的无线环境监测系统设计
引言
说话人识别又称声纹识别,是通过说话人的声音特征进行身份认证的一种生物特征识别技术。说话人识别经过60多年的研究,已经逐步应用到法律、银行等各个领域。说话人识别通过对语音信号进行处理,提取说话人语音当中的生物学个性特征,在特征空间建立不同个体的特征模型,从而实现说话人的识别。识别的关键算法包括特征提取和建立模型两个方面,参考文献从基本概念到特征提取,再到模型建立,对说话人识别中涉及的主要算法进行了详细的综述,并比较了各种算法的优劣。
实现基于嵌入式的实时说话人识别系统是说话人识别走向应用的关键步骤。随着DSP技术的发展,DSP作为数字处理专用芯片在复杂数学算法的实现上起着越来越重要的作用。参考文献在DSP上实现了说话人确认,并应用于汽车声纹锁。本文以TI公司的TDSDM642EVM为平台,实现了实时的说话人身份识别系统。
1 系统组成
说话人识别系统是一个模式识别的过程,总体上分为两个步骤:第一个步骤是训练说话人模型,第二个步骤是通过比对模型库对输入的信号进行说话人识别。其识别过程如图1所示。
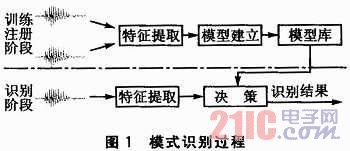
在训练注册阶段,系统主要完成说话人的特征提取以及模型特征库的建立。在识别阶段,系统根据输入的语言信号提取相应的特征,然后再与模型库中的模型进行匹配判决,最后给出识别结果。
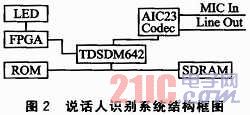
说话人识别在嵌入式系统中实现时主要完成语音采集、模型训练、匹配识别3个任务。本文采用TDSDM642EVM平台实现说话人识别系统,其结构框图如图2所示。该系统通过AIC23实现语音信号采集和播放的功能,输入的语音信号经过TDSDM642处理后,通过LED显示识别结果。 ROM中包含说话人识别程序和训练出的模型数据,并可以实时更新。SDRAM则提供了系统运行时所需的内存。