・上一文章:基于OPNET仿真平台的MANET路由协议性能分析
・下一文章:Samsung S3C2440平台上的Vxworks BSP移植
至共享存储器子系统的存取路径经过精心的重新设计,能够显著降低至较高级存储器的时延,无论所有CorePAC和数据 I/O 是否处于繁忙状态,均能维持相同的效率。
二级存储器效率 —— 与之前的系列产品相比,LL2 存储器器件和控制器的时钟运行速率更高。C66x LL2 存储器以等同于 CPU 时钟的时钟速率运行。更高的时钟频率可实现更快的访问时间,从而减少了因 L1 高速缓存失效造成的停滞,在此情况下必须从 LL2 高速缓存或 SRAM 获取存储器)。光这一项改进就自动使得从 C64X+ 或 C67X 器件进行应用升级实现了很大的速度提升,而且无需为 C66x 指令集进行重新编译。
此外,无论是对用户隐藏的还是由软件命令驱动的高速缓存一致性操作都会变得更高效,而且需要执行的周期数也更少。反之,这也意味着自动的高速缓存一致性操作(例如检测、数据移出)对处理器的干扰更小,因而停滞周期数也更少。手动的高速缓存一致性操作(例如全局或模块回写和/或无效)占用较少的周期即可完成,这就意味着在为共享存储器判优的过程中,实现CorePac 之间或 CorePac 与 DMA 主系统的同步将需要更短的等待时间。
共享存储器效率 —— 为进一步提高共享存储器的执行效率,在 CorePac 内置了扩展存储器控制器 (XMC)。对共享内部存储器 (SL2/SL3) 和外部存储器 (DDR3 SRAM) 来说,XMC 是通向 MSMC 的通道,且架构的构建基础实施在此前具有共享二级(SL2)存储器(比如TMS320C6472 DSP)的器件之上。
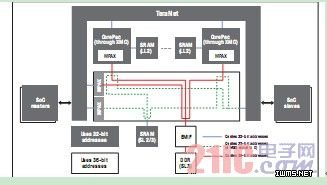
图 3 - 共享存储器架构
在以前具有 SL2 存储器的器件上,通向 SL2 的存取路径与通向 LL2的存取路径一样,在邻近内部接口处均有一个预取缓冲器。预取功能可隐藏对共享 RAM 库的访问时延,并可优化代码执行及对只读数据的存取(全面支持写操作)。XMC 虽然也遵循相同的目标,但是却进一步扩展添加了强大得多的预取功能,从而对程序执行和 R/W 数据获取提供了可与 LL2 相媲美的最佳性能。预取功能不仅能在访问存储器之前通过拉近存储器和 C66x DSP 内核之间的距离来降低存取时延,而且还能缓解其他 CorePac 和数据 I/O 通过 MSMC 争夺同一存储器资源的竞争局面。
MSMC 通过 256 位宽的总线与 XMC 相连,而 XMC 则可直接连接至用于内部 SL2/SL3 RAM 的 4 个宽 1024 位存储器组。内部存储器组使 XMC 中的预取逻辑功能能够在未来每次请求访问物理 RAM 之前获取程序和数据,从而避免后续访问停滞在 XMC。MSMC 可通过另一 256 位接口与外部存储器接口控制器直接相连,进一步将 CorePac 的高带宽接口一直扩展到外部存储器。
对于外部存储器而言,KeyStone架构可通过与共享内部存储器相同的通道进行访问,从而较之前的架构实现了显著的增强。该通道的宽度是之前器件的两倍,而速度则为一半,从而大幅降低了到达外部 DDR3 存储器控制器(通过 XMC 和 MSMC)的时延。在此前的 C6000 DSP 中以及众多的嵌入式处理器架构中,外部 CPU 和高速缓存访问是通过芯片级互连进行发布的,而 XMC 则可提供更为直接的最优通道。当从外部存储器执行程序时,其可大幅提高 L1/L2 高速缓存效率,并在多个内核与数据 I/O 对外部存储器并行判优时能够显著降低所带来的迟滞。





