・上一文章:多时钟域数据传递的Spartan-II FPGA实现
・下一文章:基于DVI和FPGA的视频叠加器设计
对各时刻的频谱序列进行傅里叶变换,图2所示时刻的频谱序列的傅里叶变换如图3所示。

从图2中可以看出,由于实际的语音是准周期信号和实际上是短时间信号的频率分析,其频谱序列不是周期性冲激函数序列的采样,而是近似三角脉冲的采样,所以其傅里叶变换的幅度谱呈现高频衰减性质。从图3中可以观察到频谱序列的幅度谱是周期信号和高频衰减信号的乘积。实际语音分析过程中各时刻频谱序列的傅里叶变换后衰减幅度差异很大,低频部分有时会出现分支脉冲的幅值大于下一个周期主脉冲的幅值,这对信号周期地分辨产生一定的干扰,而无法准确估计基频值。所以本文在确定基频时利用高频部分衰减幅度差异较小的特点,分析其周期特性并用来计算语音基频。
共振峰参数包括共振峰频率、频带宽度和幅值,共振峰信息包含在语音频谱的包络中。因此共振峰参数提取的关键是估计语音频谱包络,并认为谱包络中的最大值就是共振峰。利用语音频谱傅里叶变换相应的低频部分进行逆变换,就可以得到语音频谱的包络曲线。依据频谱包络线各峰值能量的大小确定出第1~第4共振峰,如图4所示。

对于提取参数准确性的测试,可以在时域和频域上与人工分析的结果进行比较,这种方法可以定量计算出提取算法的准确度,但工作量大不易实现。由于基频和共振峰两个基本信息是语音信号辨别的主要特征点,所以判断两个参数重建语音信号的语音质量就可了解参数提取算法的性能。语音信号重建采用谐波合成方法,即首先根据共振峰信息建立语音频谱的包络,然后根据频谱包络确定基频及其各次谐波的幅值并合成语音信号。本文应用所得到的参数重新生成语音,主观分辨合成语音的质量,据此判断参数提取算法准确度。在短时间内语音信号可以被看作是平稳信号,所以每一帧的语音频谱也可以简化为一组离散信号,离散的量化值就是基频。根据离散频谱利用式(1),式(2)合成语音信号:
![]()
V(t)为合成语音信号,FP为基频。为避免出现尖峰信号,设定了相位φn(ω)函数:
![]()
比较3种方式确定的离散频谱所合成的语音信号:
(1)直接对原语谱图离散;
(2)对所得的语谱包络离散;
(3)对根据共振峰值确定的频谱包络离散。
此方式的具体方案是:由于人耳对共振峰的参数中的中心频率敏感,而对幅值和带宽不敏感,所以本文只用共振峰的中心频率和最大幅值两个参数信息来合成语音。
根据成年人语音信号的共振峰带宽大约300 Hz,将各共振峰的带宽统一定为300 Hz。重新作语音频谱包络线时,以各共振峰中心频率值为中点、最大能量为幅度作宽度为300 Hz的门信号,然后根据新生成的包络线确定基频的各次谐波的幅值。用第一种语谱图合成语音听起来只是音质略有变化,可以清晰分辨每个音节,完整保留原语音的语调、语气和说话人音质特征等信息。这说明算法能够准确提取基频信息,而且这种合成方法可以合成出高质量的语音信号。用第二种语谱图合成的语音中说话人音质特征有些不清楚,其他方面与第一种相同。第三种语谱图和成的语音中说话人音质特征完全被过滤掉,个别音节有些含糊,但语气、语调信息完整保留。
3 共振峰语音编码
共振峰编码算法需要基频和共振峰两种参数。通过实验表明应用基频、共振峰信息不但可以重建语音中的元音和浊辅音部分,还可以重建清辅音部分。首先是因为参数提取算法在清辅音部分时所确定的基频参数不稳定,根据不稳定参数重建的语音信号会出现跳变,这种跳变信号与清辅音的频谱相似。更重要的原因人耳对于辅音的听辨要点是过渡音征,所以只要准确提供共振峰值就能重建清辅音部分。根据语音信号合成的研究表明,表示浊音信号最主要的是前三个共振峰。一个语音信号的共振峰模型,只用前三个时变共振峰频率就可以得到可懂度很好的合成浊音。考虑到特殊情况下可能会出现伪共振峰,本算法在确定编码参数时根据共振峰幅值大小保留4个共振峰参数。
3.1 参数量化
语音编码算法最主要的两个主要指标是比特率和语音质量。低速率语音编码算法要求在语音可懂的基础上最大限度地降低比特率。为确定各参数的最大量化度,我们对各参数进行不同程度量化后重新合成语音,并评价各量化程度的语音质量。
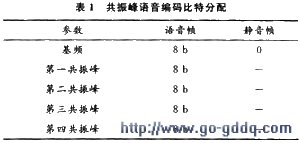
正常语音的基频变化范围为50~500 Hz,基频量化实验时发现当基频量化精度为20 Hz时,重建的语音信号仍然清晰。所以编码时基频最低可以用5 b表示,但为了提高抗误码能力用8 b对基频进行编码。共振峰的量化分为频率值量化和幅值量化。根据参数提取算法可知,共振峰曲线是基频及其各次谐波的包络线。我们可以认为语音频谱是基频及其谐波对共振峰曲线采样信号,所以可以以基频值作为描述共振峰曲线的精度。共振峰的中心频率值就可以用基频的第几次谐波确定,所以变化范围是1~32,编码时用5 b表示。人耳对共振峰幅值不敏感,通过语音实验表明当时域上以16位采样精度录制语音,信号振幅变化范围210~215时用3 b对幅值编码时就能清楚表现语音。所以对于每个共振峰可以用8 b量化,其中5 b表示中心频率,3 b表示幅值。
3.2 编码规则
编码中语音帧周期可以分为动态和固定两种形式。动态形式是每帧的周期根据基频来确定,即每帧是一个基频周期。这种方式在解码时语音清晰度自然度最好,但由于帧周期的长度小导致编码率高。固定形式是帧的周期是一定的,根据实际情况可以设定为10~40 ms。周期长度与音质成反比,与压缩率成正比。本算法中帧周期采用固定形式设定为25 ms。根据频谱能量值判断是否有语音,当没有语音时以一个0字节编码。我们采用一个字节表示静音帧,是为了提高算法的抗误码能力。
3.3 结果
用本算法对一段正常语速朗读的语音材料进行编码及解码,解码后语音可懂性好,平均码率1 400 b/s。
4 结 语
理论上只要有准确的基频和共振峰参数,就可以恢复出原语音信号除嗓音音质特征外其他所有特征。本算法所用的参数只有基频和4个共振峰,对于语音信号这些参数是分辨语音信息的特征参数。当编码信息中只含有这些参数,则可以认为就每帧信号来讲没有冗余信息,也就是对于每帧信号编码达到了最大压缩。如果在本算法基础上要进一步提高压缩率,只能针对帧与帧间的关联来设计,如矢量量化算法等。
本编码算法的延时短、复杂度低,可以用于实时的语音信号传输。在比特率、延时、复杂度3个评价指标上其性能良好,解码后语音有轻微的机器音和个别音节含糊。导致语音音质差的因素有两个:一是参数量化时出现误差,根据实验分析误差主要是共振峰量化误差,所以量化编码时根据实际要求在音质和编码率间进行选择;二是语音重建算法,本文重建时只是简单地用门函数表示共振峰幅频特性,如果能在深入研究共振峰幅频特性的基础上改进重建算法,解码后语音音质一定会得到改善。





