・上一文章:Nios II实现二频机抖陀螺工作电路设计
・下一文章:海信KFR-3601GW/BP交流变频空调电路分析
目前针对语音识别提出了很多算法,但是这些研究基本上都是基于较为纯净的语音环境,一旦待识别的环境中有噪声和干扰,语音识别就会受到严重影响.如果能实现噪声和语音的自动分离,即在识别前就获得较为纯净的语音,可以彻底解决噪声环境下的识别问题.近年来取得很大进展的盲源分离为噪声和语音的分离提供了可能.盲源分离(Blind Source Separation)的算法众多且运算复杂,经比较,其中T.Nishikawa等人提出的分阶段ICA方法(MSICA)适合有混响的噪声环境中的语音分离问题.经过计算机仿真,MSICA算法分离一段7s的语音要用时10ms以上,计算机和低速的DSPs很难满足实时要求.
针对这一算法,设计了一套以TI的TMS320C6416 DSP(简称6416)芯片为内核的语音净化系统.6416的时钟速度高达720MHz,经过使用MSICA算法的测试,该系统可以实时地对语音识别的信号进行净化处理,有效地提高语音识别系统的抗噪性和鲁棒性.
1 算法描述
1.1 语音识别信号的混合模型
1.1.1 卷积混合一般模型
语音信号的混合模型已从瞬时模型发展到卷积模型,相比瞬时模型而言卷积模型更接近真实环境.麦克风所测是卷积混迭信号,即源信号及其滤波与延迟的混迭信号的线性组合再加上其它噪声,如(1)式所示.
式(1)中,sj(t),j=1,…,N为信号源,且各源信号相互独立;xi(t),i=1,…,N为N个观测数据向量,其元素是各个麦克凤得到的输入.所以观测信号xi(t)是每个源信号sj(t)经过延时tij,并乘以因子aij(t)(冲击响应)后叠加,最后加上噪声ni(t).
1.1.2 针对语音识别的简化混合模型
一般的语音识别只有一个麦克风,根据盲源分离理论,麦克凤数应不少于信源数,所以采用主副两个麦克风输入待识别语音,为简化处理假定只有主讲话者声音s1和背景噪声s2(此背景噪声包括经过延迟的回声)两个声源.可得如图1的混合模型.
信号源s1到达两个麦克风的时间间隔为t21,且幅度值不同;s2到达两个麦克风的时间间隔为t12,幅度值也不同.又因为主信号源s1非常靠近两个麦克风,所以认为T21比T12小很多,且趋于零.于是得到相应的模型表达式的简化形式:
x1(t)=s1(t)+a12s2(t-t12)+n1(t) (2)
x2(t)=a21s1(t-t21)+s2(t)+n2(t)
1.2 MSICA算法及其实现步骤
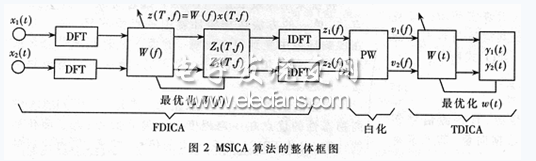
传统采用频域ICA(FDICA)或者时域ICA(TDICA)方法,单一的方法在真实环境中缺点很明显,分离效果在混响环境中受到很大影响.然而一种时频域结合多级分离的混合型ICA算法——MSICA算法可以有效解决这一问题.
该算法主要由三个步骤组成:首先,利用FDICA的高稳态性的优点在一定程度上分离源信号;为了简化后续计算,白化FDICA分离出来的信号;接着,把白化后的FDICA输出信号当作TDICA的输入信号,并用TDICA分离线留的交叉干扰分量;最后,TDICA的输出信号即为分离信号.算法框图如图2所示.
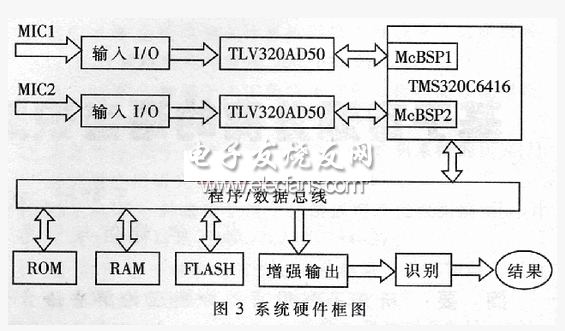
2 DSP硬件系统设计
2.1 硬件结构
为实现上述算法设计了DSP语音分离系统,该系统主要参数如下:
·TMS320C6416 DSP;
·16M words FLASH ROM;
·两个EMIF:64-Bit EMIFA和16-Bit EMIFB;
·133MHz的16MB SDRAM;
·两个16-bit立体声CODEC:TLV320AD50.
TMS320C6416有很高的信号处理能力以及丰富的片内存储咕嘟和片内外设,且有两级内部存储结构.第一级L1缓存包含各为16KB的程序和数据存储器,第二级L2包含1024KB的存储空间.第一级只能作为缓存而第二级可以被设置为部分静态RAM和部分缓存.在语音净化系统中,设置L2为4通道256KB缓存和768KB静态RAM.这种配置使用了最大允许的缓存,是因为MSICA算法将处理大量的数据,访问外部存储器会有瓶颈,而大缓存可以将诸如中断服务程序、常用函数的代码、软件堆栈等关键数据段和反复使用的系数存储于片内存储器中,从而大大提高内部存储空间的使用效率.6416的两个多通道缓冲串口(McBSP)用作数据的输入输出端口.模拟接口芯片TLV320AD50可以提供16bit的数/模、模/数转换,最大转换率是22.5kHz.采样率为8kHz,两个TLV320AD50分别通过McBSP与TMS320C6416相连.两路混合语音信号通过模拟接口电路转化为数字信号,两路数字信号通过TMS320C6416的两个McBSP输入,根据语音特征存储中存储的语音特征进行语音分离,分离出纯净的特识别语音,进行语音识别,最后输出识别结果.系统框图见图3.