・上一文章:奔驰C63 AMG轿车发动机怠速抖动
・下一文章:日本产6130型柴油机飞车故障排除
现在,各个汽车厂商在动力和排量之间的差异已经不再明显,而科技化的个性功能—车载互联、操作系统及各种科技元素是汽车厂商吸引消费者的重要手段之一。手势控制在人们日常生活中的应用越来越广泛,比如说手势控制电脑、手势控制电视,还有更加智能的是利用手势控制摄像头来隔空玩游戏。目前,手势控制是继语音控制之后另一项受到许多汽车厂商追捧的技术,手势控制可以让驾驶人在驾驶时简单地挥挥手或做出几个动作就能对车载功能进行控制,与语音控制相比,准确率更高,同时也更方便,毕竟有些人觉得语音控制汽车系统,尤其是在有其他乘客时非常尴尬。手势控制汽车就是通过车载摄像头识别特定手势,以此来替代汽车仪表盘上的各种旋钮和按钮。手势控制的最大优势就是可简化操作,让驾驶人可更加快捷地实现各种操作。
1 手势识别技术
手势控制的核心是手势识别技术,就目前的技术而言,大多数手势识别采用的是计算机视觉技术。手势识别技术由简单粗略的到复杂精细的,大致可以分为二维手型识别、二维手势识别和三维手势识别3个等级。二维只是一个平面空间,可用X坐标、Y坐标组成的坐标信息来表示一个物体在二维空间中的坐标位置,就像一幅画出现在一面墙上的位置。而三维则是在此基础上增加了“深度”(Z坐标)的信息,这里的“深度”并不是现实生活中所说的那个深度,这个“深度”表达的是“纵深”,理解为相对于眼睛的“远度”也许更加贴切,就像是鱼缸中的金鱼,它可以在你面前上下左右游动,也可能离你更远或者更近。前两种手势识别技术,完全是基于二维层面的,只需要不含“深度”信息的二维信息作为输入即可,就像拍照所得的相片一样,只需要使用单个摄像头捕捉到的二维图像作为输入,然后通过计算机视觉技术对输入的二维图像进行分析,获取信息,从而实现手势识别。而第三种手势识别技术,是基于三维层面的,三维手势识别与二维手势识别的最根本区别就在于,三维手势识别需要的输入是包含有“深度”的信息,这就使得三维手势识别在硬件和软件两方面都比二维手势识别要复杂得多,当然三维识别也能够识别更多的动作。对于一般的简单操作,比如只是想在播放视频时暂停或继续放映,二维手势识别就足够了,但对于一些复杂的人机交互,则只能采用三维手势识别技术。
1.1二维手型识别
二维手型识别也可称为静态二维手势识别,识别的是手势中最简单的一类。这种技术在获取二维信息输入之后,可以识别几个静态的手势,比如握拳或者五指张开,其代表公司是被Google收购的Flutter。在使用其软件后,驾驶人可以用几个手型来控制播放器,将手掌举起来放到摄像头前,视频就开始播放;再把手掌放到摄像头前,视频就暂停播放。“静态”是这种二维手势识别技术的重要特征,这种技术只能识别手势的“状态”,而不能感知手势的 “持续变化”,举个例子来说,如果将这种技术用在猜拳上的话,它可以识别出石头、剪刀和布的手势状态,但对除此之外的手势,便一无所知。因此这种技术说到底是一种模式匹配技术,通过计算机视觉算法分析图像,和预设的图像模式进行比对,从而理解这种手势的含义。这种技术的不足之处显而易见一一只可以识别预设好的状态,拓展性差,控制感很弱,驾驶人只能实现最基础的人机交互功能。
1.2二维手势识别
二维手势识别,比起二维手型识别来说稍难一些,但仍然停留在二维的层面上,基本不含“深度”信息。这种技术不仅可以识别手型,还可以识别一些简单的二维手势动作,比如对着摄像头挥挥手,其代表公司是来自以色列的PointGrab、 Eyesight和ExtremeReality。二维手势识别拥有了动态的特征,可以追踪手势的动,进而识别将手势和手部运动结合在一起的复杂动作。这样就把手势识别的范围真正拓展到二维平面上了,驾驶人不仅可以通过手势来控制计算机播放/暂停,还可以实现前进、后退、向上翻页、向下滚动这些需求二维坐标变更信息的复杂操作。这种技术虽然在硬件要求上和二维手型识别并无区别,但是得益于更加先进的计算机视觉算法,可以获得更加丰富的人机交互内容。在使用体验上也提高了一个档次,从纯粹的状态控制变成了比较丰富的平面控制。
1.3三维手势识别
当今手势识别领域的重头戏是三维手势识别。三维手势识别需要的输入信息包含有“深度”的信息,可以识别各种手型、手势和动作。相比于前两种二维手势识别技术,三维手势识别不能再只使用单个普通摄像头,因为单个普通摄像头无法提供“深度”信息。要得到“深度”信息需要特别的硬件,目前世界上主要有3种硬件实现方式—光飞时间(Time of Flight)、结构光(Structure Light)、多角成像 (Multi-camera再加上新的先进的计算机视觉软件算法即可实现三维手势识别。下面阐述三维手势识别的三维成像硬件原理。
1.3.1光飞时间(Time of Flight,简称ToF)三维手势识别
光飞时间(ToF )是SoftKinetic公司所采用的技术,该公司为业界巨鳄Intel提供带手势识别功能的三维摄像头,同时,这一硬件技术也是微软新一代Kinect所使用的。光飞时间的基本原理是加载一个发光元件,发光元件发出的光子在碰到物体表面后会反射回来。使用一个特别的CMOS传感器来捕捉这些由发光元件发出、又从物体表面反射回来的光子,就能得到光子的飞行时间。根据光子飞行时间进而可以推算出光子飞行的距离,也就得到了物体的“深度”信息。就计算上而言,光飞时间是三维手势识别中最简单的,不需要任何计算机视觉方面的计算。由于光的传播速度非常快,基于ToF技术的感光芯片需要飞秒级的快门来测量光飞行时间,这也是TOF技术难以普及的原因之一,因为这样的感光芯片成本过高。利用ToF技术进行手势控制,需要一个3D摄像头进行配合,摄像头的用处是监控并识别手势变化。摄像头内置有红外LED光发射装置与接收装置,根据光线发射与接收之间的时间差来分析出手势的变化。最终得到的数据会传递给车载系统的控制单元,由控制单元调出与识别出的手势相对应的功能。
当然,还有一种方式是将光脉冲改为无线电波,极高频毫米波无线电波也同样可以用来捕捉动作、距离、速度等信息,感应误差精细到毫米。然而,如何把具有如此精度的设备微小化是一件十分艰难的事情,最难的地方在于微小化会影响器件的发射功率和效率、感应灵敏度等。
1.3.2结构光(Structure Light)三维手势识别
结构光技术的基本原理与ToF技术类似,所不同之处在于其采用的是具有点、线或面等模式图案的光。结构光的代表应用产品是PrimeSense公司为微软家XBOX 360所做的Kinect一代。结构光技术的基本原理是,加载一个激光发射器,在激光投射器外面放一个刻有特定图样的光栅,激光通过光栅进行投射成像时会发生折射,从而使得激光最终在物体表面上的落点产生位移。也就是说,激光发射器将结构光投射至前方的人体表面,再使用红外传感器接收人体反射的结构光图案,然后,处理芯片根据接收图案在摄像机上的位置和形变程度来计算物体、人体的空间信息。当物体距离激光发射器比较近时,折射而产生的位移较小;当物体距离激光发射器较远时,折射而产生的位移会相应变大。这时使用一个摄像头来检测采集投射到物体表面上的图样,通过图样的位移变化,就能用算法计算出物体的位置和“深度”信息,进而复原整个三维空间,即可进行三维物体的识别。以Kinect一代的结构光技术来说,因为依赖于激光折射后产生的落点位移,因此在太近的距离上,折射导致的位移尚不明显,使用该技术就不能太精确地计算出“深度”信息,所以1 m~4 m是其最佳应用范围。
1.3.3多角成像(Multi-camera)三维手势识别
多角成像这一技术的代表产品是Leap Motion公司的同名产品和Usens公司的Fingo。多角成像技术与立体成像技术相同,这种技术的基本原理是使用2个或2个以上的摄像头同时摄取图像,就好像是人类用双眼、昆虫用多目复眼来观察世界,通过比对这些不同摄像头在同一时刻获得的图像的差别,使用算法来计算“深度”信息,从而多角三维成像。这里以2个摄像头成像来简单说明其原理。双摄像头测距是根据几何原理来计算“深度”信息的。如图1所示,使用2台摄像机对当前环境进行拍摄,得到2幅针对同一环境的不同视角照片,实际上就是模拟了人眼工作的原理。因为2台摄像机的各项参数及它们之间相对位置的关系是已知的,只要找出相同物体(枫叶)在不同画面中的位置,便能通过算法计算出该物体(枫叶)距离摄像头的“深度”。
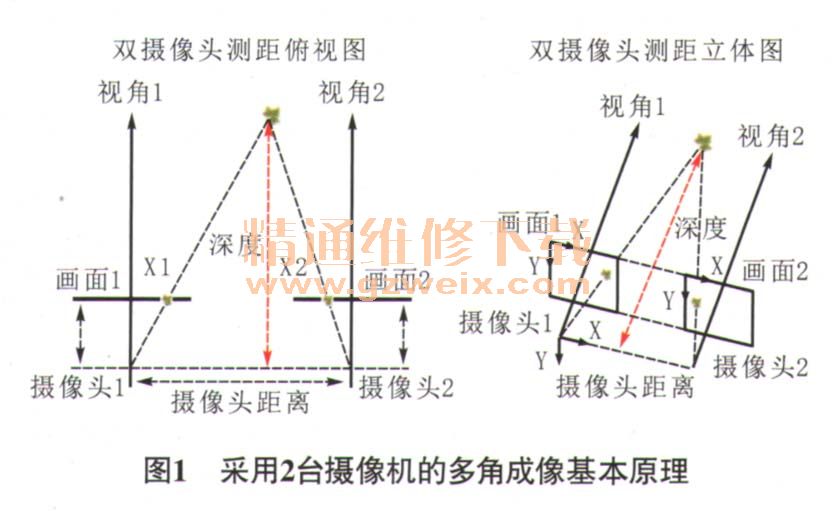
多角成像是三维手势识别技术中硬件要求最低,但同时也是最难实现的。多角成像不需要任何额外的特殊设备,完全依赖于计算机视觉算法来匹配2张图片里的相同目标。相比于结构光或光飞时间这两项技术成本高、功耗大的缺点,多角成像能提供“价廉物美”的三维手势识别效果。





